<Extracted from D4.5, chapter 5>
Using Background Domain Knowledge
According to well-established standards in Ontology Engineering domain, once the expert creates a domain-specific ontology, the next step is to populate the empty schema with background domain knowledge. As background domain knowledge we consider any information stored in an ontology that is relevant to the realisations of concepts (i.e. instances) and their relations in the domain, and not to the concept hierarchies and the structure itself.
The ontology population process, i.e. the instantiation of new knowledge in an ontology-based representation could be a time-consuming and error-prone task, if done manually. As a result, research has shifted attention to automating the process of identifying and adding new instances from an external source into an ontology [Buitelaar & Cimiano, 2008].
Within the context of PERICLES project we have developed PROPheT, a novel application that enables instance extraction and ontology population from Linked Open Data (LOD) sources, such as DBpedia and Europeana, through a user-friendly graphical user interface [Mitzias et al., 2016; PERICLES D4.3, 2016]. PROPheT offers access to available LOD sources, facilitating through different types of instance extraction-related functionalities the discovery, reusability and extensibility of knowledge in any domain of interest. PROPheT simplifies the way of communicating information with LOD sources, without needing any high level of expertise for querying, accessing and storing the available data.
The applicability and efficiency of ontological inference methods, based on either class/property declarations (axioms) or SPIN rules, is highly dependent on the amount of information being stored in the examined ontology. The added knowledge can potentially lead to better classification results, since, in other words, the less the information stored within an ontology the less the axioms/rules that are met in reasoning process.
PROPheT can be the proper tool to be deployed for enriching instances in an ontology, so as to perform reasoning on the enriched instances. For example, as presented in sub-section “Inference based on Domain and Range Restrictions”, if we have an instance of an unknown class that is connected with an instance of a dva:VideoStream class via the property dva:hasAspectRatio, then the aforementioned instance will be classified to dva:AspectRatio class (see Fig. 1).
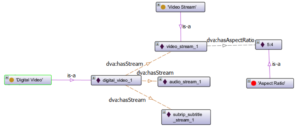
Fig. 1. Instances classified either manually (yellow circles), or automatically (red circle) through the inference of a reasoner that is based on relevant instances, relations and their values.
Apart from the content of an ontology that PROPheT can enrich, our tool can instantiate information about the use-context of instances in the ontology. By the term use-context we considered any relevant information regarding the “context of use” of entities (digital objects) in their environment [Kontopoulos et al., 2016]. As already stated in [PERICLES D4.3, 2016], the representation of use-context capitalises on the LRM notions defined as dependency descriptors. Through a relevant parameter selection in PROPheT, the tool gives the ability to the user to create links between populated instances and instances from external sources. An indicative description of the triples that are automatically created in a sample population process of a single instance, are given below in the RDF Turtle form:
| @prefix my_source: <http://PROPheT_sample_ontology#> . @prefix external_source: <http://external_sample_ontology#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix lrm: <http://xrce.xerox.com/LRM#> . my_source:dependency_xyz rdf:type lrm:Dependency . my_source:dependency_xyz lrm:from my_source:populated_instance_klm . my_source:dependency_xyz lrm:to external_source:instance_abc . |
where dependency_xyz is the new instance of dependency created, that links the newly populated_instance_klm with data derived from the instance_abc of the external LOD source. As stated in Inference Based on Class Axioms Section, if more details are stored in the ontology regarding the lrm:from part of each dependency, then further classification of the instance of dependency into HardwareDependency, SoftwareDependency or DataDependency class, will be feasible.