![]()
This section is extracted from the deliverable D4.1 Initial version of environment information extraction tools [Corubolo, F. et al (2014)], p.14-17
Please refer to the further reading list for the names referenced to in [ ].
What is metadata?
Metadata can be defined as the information necessary to find and use a digital object during its lifetime [N. I. S. O. (2004)].
This definition covers a wide variety of information, and was further refined by the Consultative Committee for Space Data Systems in their reference model for an Open Archival Information System (OAIS) [CCSDS, J. (2012)].
OAIS covers the information necessary for the long-term storage of digital objects, and identifies a number of high-level metadata categories, as follows.
- The Descriptive Information (DI) consists of information necessary to understand the digital object (DO), for example its name, a description of its intended use, when and where it was created, etc.
- The Preservation Description Information (PDI) consists of all the information necessary to ensure that the digital object can be preserved, including fixity (e.g. a checksum), access rights, unique identifier, context information (described in more detail in the following subsection) and provenance, which describes how the object was created.
- The final category arises from the fact that the OAIS manages not the digital object itself, but information packages which consist of the digital object as well as the DI, PDI and information required to interpret the contents of the digital object (which is described by the Representation Information (RI)). The Packaging Information (PI) category describes how the information package is arranged such that individual elements can be accessed.
Why metadata?
Metadata may be treated as a separate entity, as it can be accessed without accessing the digital object, but the lack of metadata adversely affects the access to or reuse of the digital object. While such information is essential for the reuse of the digital object it is not in general sufficient; information concerning the external relationships of a digital object, whether to other digital object, stakeholder communities, or other aspects of the environment within which a digital object is created or curated, also need to be taken into account to ensure that the digital object can be used fully and appropriately.
Metadata may be held internally in a digital object, e.g. in the header of a structured file, or externally, e.g. in a database, or separate data structures such as in file system extended attributes. The location of metadata is an important factor for Long Term Digital Preservation (LTDP), as it will have consequences on the availability of the information when for example the data is moved to an external location, as in such event external metadata is in danger of being lost. Just to give a short motivating example, of potentially useful metadata that is stored in an external location, we take the example of the Apple OS X spotlight metadata. When downloading data from a web browser, OS X stores provenance information about the URL where the data was downloaded from. Such provenance information (that can be useful to understand the origin of the data) is lost, if proper action is not taken, as soon as the data is archived to an external location (as for example when archiving it to a ZIP file) as it is part of the OS indexing engine database.
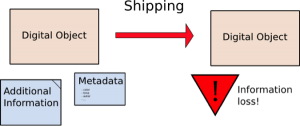
The issue is illustrated in the above figure where the relationship between information that is needed to use a DO and the DO is implicit and is lost when the DO is transported to a new location. This can be solved in two steps:
- We first need to identify and extract the useful information from the DO environment (external information). We are specifically addressing this issue with the definition of Significant Environment Information (next chapter), and with the PET software, described in this module.
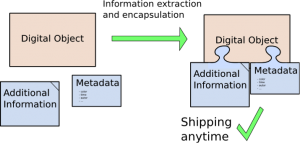
- Such information needs to be encapsulated together with the DO in a second step (discussed in the next module), so that the information is not lost when DOs are moved or migrated (see also next figure).
This is one of the reasons why we consider the extraction, and successive encapsulation of such external information as an important step to guarantee long term use of DOs.
Metadata standards
Standard file formats have standard structural metadata (e.g. MPEG21), and de facto standards (e.g. the Text Encoding Initiative (TEL) exist for popular formats. The situation on standardisation for the descriptive part of the RI is more complex due to the different needs of different communities, although many approaches contain the [Dublin Core (2008)] metadata element set as a core. A catalogue of metadata standards for different communities can be found on the Digital Curation Centre website [DCC (2013)].
See also: our early analysis of metadata standards and their information content across standard on the PERICLES public wiki: http://goo.gl/sJ1Z1m
on the PERICLES public wiki: http://goo.gl/sJ1Z1m
As part of the work to analyse existing standards and determine useful information to collect as well as existing gaps, we have built a comparative table illustrating the different standards and features, as illustrated in the above metadata attributes table.
This table illustrates the scope of a number of current metadata standards, and drove us to aim at the collection of a broader set of information, defined on the uses of DO as opposed to taking a standards driven approach. Our first attempt at determining what to capture was to determine this based on the different existing standards and their classifications. After some work, it was clear that a lot of time would be required for the classification and mapping of existing standards, and that would result in any case in subjective output. We do not try to imply that such classifications aren’t useful in many cases, but as a number of standards and classifications already exist, we determined that a different approach would be beneficial and would fill a gap in the current approaches.
The standards were based on particular uses and so offer some clues in those domains as to what constitutes the useful environment information to collect. Still, for domain specific standards, it’s not so easy to map across domains, while in the case of the generic standards they of course are generic and cover a subset of what’s needed and not everything so the users are left with the task of defining a metadata schema for their own domain.
We consider that what really matters is the capability of making use of the information, and therefore we decided that this is what can help and guide our selection of the environment information.
Starting from the data use and looking for the required information will allow to gather a broader scope of information that could partially be ignored when using a standard driven approach, covering what is necessary for the use and reuse of the information by the use communities, and to observe its change in time.